明德扬专注于FPGA培训:设有 FPGA网络班、FPGA就业班
PCIExpress通常有两种尺寸:1车道和16车道,1车道用于普通板卡,16车道用于图形卡。
连接器
单车道连接器有36个触点,排列成两排18个触点.
这里有个俯瞰。

在36个触点中,只有6个对数据传输有用,其余的是电源引脚和其他辅助信号。这6个功能触点分3对使用:
-
一个叫REFCLK的时钟对。
-
一种叫PER的接收对。
-
一种叫做PET的传输对。

这两对通常被称为“差分对”,因为来自一对信号的每一个信号都带有相同的信号,但其中一个信号与另一个信号相反。使用差动对的原因主要是传动的可靠性,稍后将更详细地讨论。
在PCIExpress第1代(或简单地说是“GEN 1”)中,PET和PER对的数据传输速度为2.5Gbps。第二代是那个的两倍。
看着龙-英在板上,我们可以识别FPGA下面的PET对。

为了正确地工作,差动副中的线需要电耦合,没有阻抗不连续,这在实际中意味着“保持紧密”和“没有尖锐的角度”。这就是龙-E的PET对蛇形形状的原因。板的另一边显示了另外两对蛇形对REFCLK和PER。
PCI Express x16
为了提高速度,可以使用多条车道。REFCLK对不需要重复,例如,带有2车道的PCIExpress使用5对(1 REFCLK+2 PET+2 PER)。
图形板通常使用16车道连接器,这通常被称为PCIExpress x16。
PCI Express 2-拓扑
点对点体系结构
在2.5Gsps时,PCIExpress Gen1的线路速度是33 MHz遗留PCI速度的75倍。
那件事怎么可能?只是因为pci Express是点对点总线。
还记得PCI是如何共享总线的吗?

对于PCI,必须指定足够的时间让信号在每个时钟周期内稳定下来。这是因为PCI总线的每一行都是沿着同一总线上的PCI连接器和板共享的。使用pci Express,每个信号都是点对点,这意味着没有更多的稳定时间,而且线路速度可以更高。
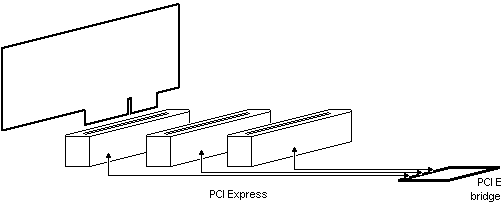
例如,如果主板有两个单车道连接器和一个16车道连接器,则需要6+6+34=桥上的46个引脚,仅供REFCLK、PER和宠物使用(因为不允许共享)。
时钟恢复
在2.5GHz的速度下,点对点架构仍然是一个挑战,因为每个比特的持续时间太短,以至于定时抖动(围绕每一位到达的时间不确定性)成为一个问题。即使每个信号对都有一个伴随着它发送的相关时钟对,该时钟对也会受到定时抖动的影响。因此,取而代之的是一种叫做“时钟恢复”的新技术。
时钟恢复很简单。基本上,对于每个信号对,对接收器都会查看信号转换(位0,后面跟着位1,反之亦然),从中可以推断出周围比特的位置。一个问题是,如果多个连续比特以相同的值传输(如许多0‘s),则不会出现信号转换。因此,额外的比特被发送,以确保信号转换不太遥远(这“重新同步”时钟恢复机制)。
额外的比特使用一种称为8b/10b编码的方案发送,因此对于每8位有用的数据,实际以一种保证足够信号转换的特定方式传输10位(20%的开销)。但这也意味着,在2.5GHz时,我们每对只获得250 Mbps的有效带宽(而不是没有编码开销的312 MBps)。
微分对
现在还记得信号是以差分对发送的事实吗?这有许多优点:
-
它更不受外界干扰。
-
它能在低电压下工作。
-
..最后但并非最不重要的一点:这有助于时钟恢复获得精确的信号转换。
差分对有一个明显的缺点:传输一个信号需要两倍多的电线。
PCI Express 2-数据包及堆栈
分组交易
PCI Express是一种串行总线。或者是?从计算机的角度来看,它是一种可以实现读写事务的常规总线。
诀窍是所有的操作都是打包的。让我们假设CPU想要向设备写入一些数据。它将订单转发到PCIExpress桥,然后PCI Express桥创建一个数据包。该数据包包含要写入的地址和数据,并被串行地转发到目标设备,该设备解除写入顺序并执行它。
如果CPU想要读取呢?同样,网桥将一个数据包转发给目标设备,该设备现在必须执行读取,创建返回数据包并将其发送到桥接器。
所有这些在实践中都很容易做到,谢谢.
PCIExpress堆栈
让数据包在电线上可靠地流动需要一些魔法。由于分组以非常高的速度串行传输,它们必须被反序列化/组装,在目的地被解码(删除8b/10b编码),解交织(如果使用多条车道),并检查是否有线路损坏(CRC检查)。
听起来很复杂?很可能是。问题是,我们并不在乎,因为大多数复杂性都是在由三个层组成的“PCIExpress堆栈”中处理的。
-
物理层。
-
数据链路层。
-
事务层。
前两层是在PCIExpress FPGA内核(通常是硬核和软核的组合)中为我们实现的,并处理所有的复杂性。作为一个用户,我们只在交易层工作,那里的生活很容易,天空是蓝色的,女孩是美丽的。
详情如下:
-
物理层:那是引脚移动的地方。8b/10b编码/解码和车道拆卸/重新组装是在那里进行的。
-
数据链路层:在那里检查数据完整性(CRCS),并在需要时重新传输数据包(希望很少发生)。
-
事务层:这是用户级别。一旦一个包到达这里,它保证是良好的数据。
好数据?太好了,这就是我们想要的!
让我们看看在事务层中是如何工作的。
PCIE--事务层简介
在事务层,我们接收“数据包”。有一个32位的总线,数据包到达总线上(数据包长度总是32位的倍数)。也许一个数据包会说“在地址0xABCD上写数据0x1234”,而另一个数据包会说“从地址0xDCBA读取(并返回一个响应包)”。
数据包有多种类型:内存读取、内存写入、I/O读取、I/O写入、消息、完成等。我们在事务层的工作是接受数据包并发出数据包。数据包以一种称为“事务层数据包”(TLP)的特定格式呈现给我们,到达总线上的每一个32位数据都被称为“双字”(简称DW)。
所以一个数据包(抱歉,TLP)是一堆DWS。
TLP的外观
TLPS很容易解释。这是它们的总体结构。
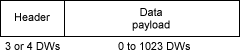
头包含3或4个DWS,但是最重要的字段是第一个DW的一部分。

“fmt”字段告诉报头多长时间,以及是否存在数据有效负载。

然后与“Type”一起描述TLP操作。TLP报头内容的其余部分取决于TLP操作。
例如,这里有一个32位的内存写tlp头,您可以看到写入地址在报头的末尾(要写入的数据在报头之后的有效负载中)。
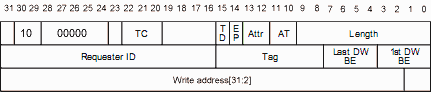
“fmt”字段是“10”,意思是“3 dw,with data”。这是有道理的,内存写需要数据来写,所以当在头后获得数据有效负载时,我们将数据写入某个内存(或以某种方式使用它),我们就完成了它。字段“Length”指示负载中有多少DWS(从0到1023)。通常,它是一个要写入的DW,在这种情况下,长度等于1,而总TLP长度是4 DWS(头部3,有效负载1)。
现在读一下记忆怎么样?不知怎么的,我们必须返回数据。
用数据完成
如果TLP是一个内存读,而不是写,我们必须执行读,然后响应。对于这种响应,有一个特殊的TLP,称为CPLD(用数据完成),它的有效载荷包含我们想要返回的数据。
让我们仔细看看32位内存读取tlp头-它非常类似于我们之前的32位内存写入。
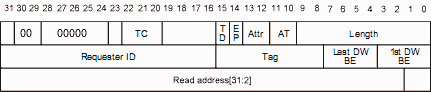
一个不同之处是fmt=00,意思是“没有数据”。有道理,我们不需要数据来读取,只需要地址。但我们现在必须用数据来回应。同样重要的是,无论谁要求阅读,都需要回复.你看到问题了吗?
好的,我们收到了一个读取请求。它来自CPU吗?还是中断控制器?还是用图形卡?毕竟,许多设备都能够发出这样的请求。答案是在“请求者ID”中给出的-它显示了请求读取的人。所以当我们创建CPLD TLP时,我们必须重新记录其中的“请求者ID”。这样,它将通过PCI Express桥路由到它所属的位置。顺便说一句,我们还必须重新复制“标记”(这在多次读取挂起的情况下非常有用)。
TLP尺寸
一个典型的32位地址/数据存储器读取TLP是由头部中的3 DWS和无有效载荷(所以96位总计)组成的,而类似的内存写入是由4 DWS组成(3用于报头,1用于有效负载)。这在带宽方面不是很有效,因为TLP报头开销很大,所以最好在可能的情况下使用更大的TLP有效负载。TLP有效负载理论上可以达到1023 DWS,对于突发读写非常方便,尽管PC机可以将最大大小限制在较低的值(32 DWS是典型的)。
PCI Express 2-XILINX 篇
Xilinx使用PCI Express变得容易-他们提供了一个免费的PCIExpress核心(称为“Endpoint Block Plus”)和一个向导来配置它,所有这些都在他们的免费版本的ISE中-ISE WebPack.
所以让我们启动Xilinx核心生成器并选择Endpoint Block Plus。

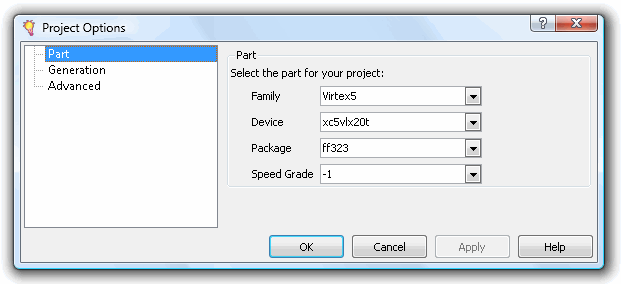
核心是不活动的,我们需要使用File->NewProject来创建一个项目并选择一个FPGA(这里我们使用的是Drag-E,所以我们选择Virtex-5).
..并选择您最喜欢的语言(在“世代”选项卡中)。
现在,端点块+核心变为活动,您可以双击它来启动向导。
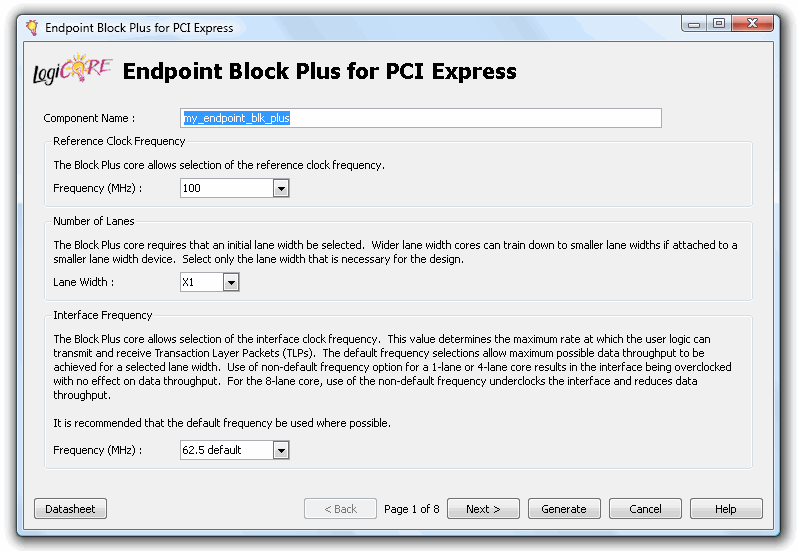
"." newtip="在第一页上,给组件命名。这里我们选择了“my_终结点_blk_plus”。其余的对Drag-E来说都是可以的,所以点击“Next>”。" style="box-sizing:inherit;">在第一页上,给组件命名。这里我们选择了“my_终结点_blk_plus”。其余的对Drag-E来说都是可以的,所以点击“Next>”。
现在您可以更改供应商/设备ID.。
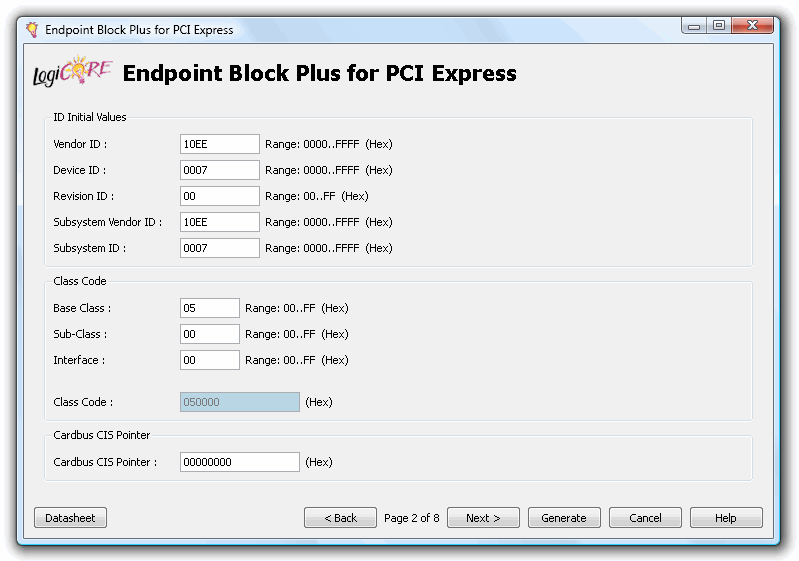
..地址空间。
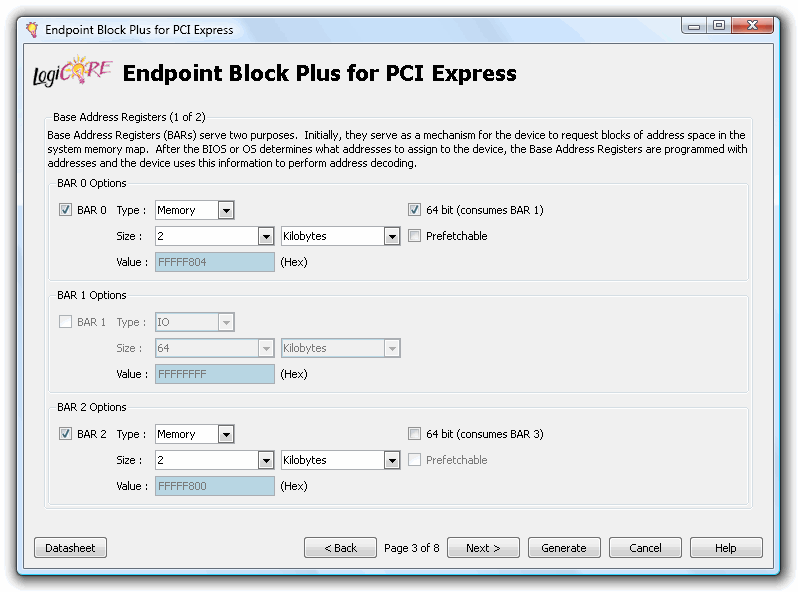
接下来的页面没有多大兴趣,所以单击“Generate”生成核心及其文档。
我们现在准备好创建我们的第一个PCIExpress FPGA位文件,在一个FPGA中编程,并生成真正的PCIExpress流量。